大规模数据查找问题——算法系列教程(c++版)
梦想不会自己发光,真正闪耀的是那个为梦狂奔的你。献给知行的孩子们!(Eric.He著)
在查找问题中,分治思想能大幅降低时间复杂度,实现高效检索——其中二分查找是有序数据查找的“效率标杆”,快速选择算法则是Top-K问题的最优解之一。本文将结合实例,详细讲解这两种基于分治的查找算法。
分治算法解决查找问题的通用步骤:
- 分解(Divide):将原数据集合拆分为两个或多个独立的子集合(通常是等规模拆分,保证效率);
- 治理(Conquer):根据查找目标,选择符合条件的子集合递归求解(不符合条件的子集合可直接舍弃,实现剪枝);
- 合并(Combine):查找问题的子问题结果即为原问题结果(无需额外合并操作,这是查找问题与排序、合并问题的核心区别)。
一、二分查找(Binary Search)——有序数据的高效查找
二分查找适用于有序数据集合(升序或降序),用于快速查找目标元素的位置。其核心优势是通过“每次舍弃一半不符合条件的区间”,将线性查找的O(n)时间复杂度降至O(log n),是有序数据查找的最优算法。
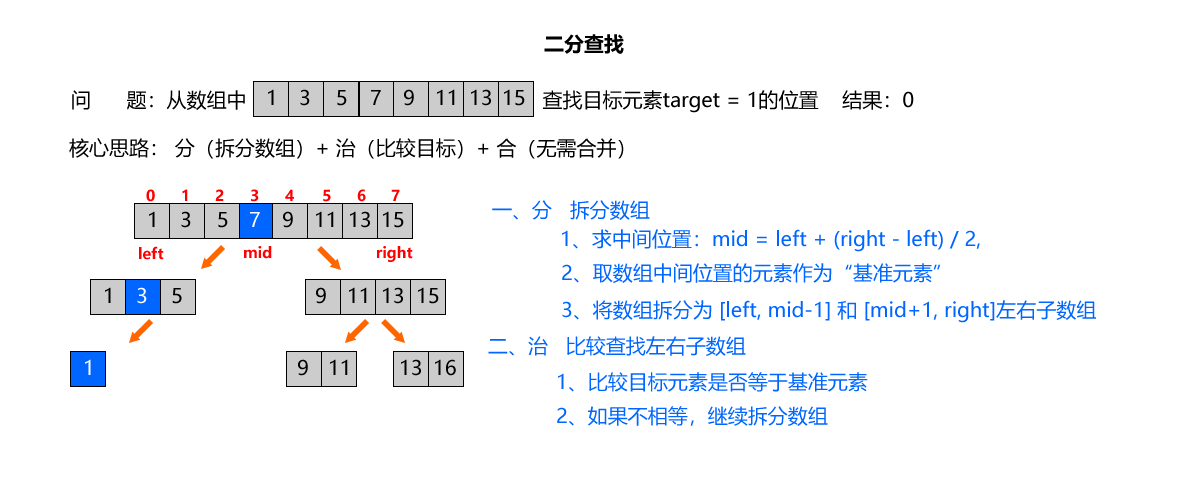
问题描述:
- 给定升序数组nums = [1, 3, 5, 7, 9, 11, 13, 15],查找目标元素target = 1
算法解析:
- 分 (Divide)
取数组中间位置的元素作为“基准元素”,将数组拆分为“左子区间([0, mid-1])”和“右子区间([mid+1, n-1])”两个子问题;
- 治 (Conquer)
- 若基准元素等于目标元素:直接返回基准元素的索引(找到目标);
- 若基准元素大于目标元素:目标元素仅可能在左子区间,递归查找左子区间;
- 若基准元素小于目标元素:目标元素仅可能在右子区间,递归查找右子区间;
- 合 (Combine)
子区间的查找结果即为原数组的查找结果(无需合并,找到即返回,未找到则返回-1)。
算法步骤:
- 第一次mid = 3,nums[mid] = 7 > 1,递归查找左子区间:left = 0,right = 2;
- 第二次mid = 1,nums[mid] = 3 > 1,递归查找左子区间:left = 0,right = 0;
- 第三次mid = 0,nums[mid] = 1 == 1,直接返回索引0;
若查找目标元素target = 4(不存在),步骤补充:
- 首次mid = 3,nums[mid] = 7 > 4,递归查找左子区间:left = 0,right = 2;
- 第二次mid = 1,nums[mid] = 3 < 4,递归查找右子区间:left = 2,right = 2;
- 第三次mid = 2,nums[mid] = 5 > 4,递归查找左子区间:left = 2,right = 1;
- 此时left > right,说明无目标元素,返回-1。
二分查找有“递归实现”和“迭代实现”两种方式,迭代实现无需额外栈空间,效率更高,实际开发中更常用。
迭代实现:
#include <iostream>
#include <vector>
using namespace std;
// 二分查找:返回目标元素的索引,未找到返回-1
int binarySearch(vector<int>& nums, int target) {
int left = 0; // 左指针:区间起始
int right = nums.size() - 1; // 右指针:区间末尾
while (left <= right) { // 区间有效(left > right时无目标元素)
int mid = left + (right - left) / 2; // 计算中间索引(避免left+right溢出)
if (nums[mid] == target) {
return mid; // 找到目标,返回索引
} else if (nums[mid] > target) {
right = mid - 1; // 目标在左子区间,缩小右边界
} else {
left = mid + 1; // 目标在右子区间,缩小左边界
}
}
return -1; // 未找到目标
}
// 测试案例
int main() {
vector<int> nums = {1, 3, 5, 7, 9, 11, 13, 15};
int target1 = 7;
int target2 = 4;
cout << "目标" << target1 << "的索引:" << binarySearch(nums, target1) << endl; // 输出3
cout << "目标" << target2 << "的索引:" << binarySearch(nums, target2) << endl; // 输出-1
return 0;
}
输出结果
目标7的索引:3
目标4的索引:-1
递归实现:
#include <iostream>
#include <vector>
using namespace std;
// 递归辅助函数:left和right为当前查找区间
int binarySearchRecur(vector<int>& nums, int target, int left, int right) {
if (left > right) return -1; // 递归终止条件:区间无效
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] > target) {
return binarySearchRecur(nums, target, left, mid - 1); // 递归左子区间
} else {
return binarySearchRecur(nums, target, mid + 1, right); // 递归右子区间
}
}
// 对外接口
int binarySearch(vector<int>& nums, int target) {
return binarySearchRecur(nums, target, 0, nums.size() - 1);
}
// 测试案例
int main() {
vector<int> nums = {1, 3, 5, 7, 9, 11, 13, 15};
int target1 = 11;
int target2 = 2;
cout << "目标" << target1 << "的索引:" << binarySearch(nums, target1) << endl; // 输出5
cout << "目标" << target2 << "的索引:" << binarySearch(nums, target2) << endl; // 输出-1
return 0;
}
输出结果
目标7的索引:5
目标4的索引:-1
二、快速选择算法(Quick Select)——Top-K问题的高效求解
Top-K问题是指从无序数据集合中,快速找到第K大(或第K小)的元素(如“找出班级成绩第3名”“找出数组中第5大的数”)。传统解法是“排序后取第K个元素”,时间复杂度O(n log n);而快速选择算法基于分治思想,平均时间复杂度为O(n),最坏时间复杂度O(n²)(可通过随机选择基准元素优化为近似O(n)),是Top-K问题的最优解法。
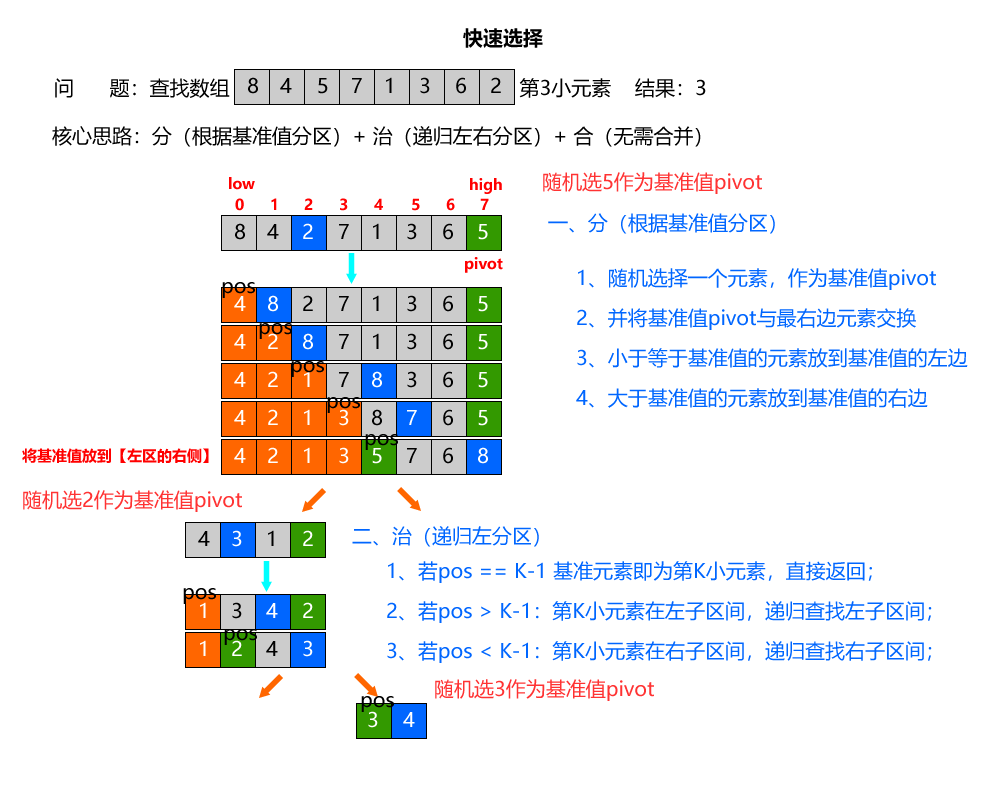
问题描述:
- 给定无序数组nums = [8, 4, 5, 7, 1, 3, 6, 2],查找第3小元素(K=3)
算法解析:
快速选择算法的核心逻辑源于快速排序(Quick Sort),但无需完全排序:
- 分 (Divide)
随机选择数组中的一个元素作为“基准元素(pivot)”,并将基准值pivot与最右边元素交换。通过“分区(partition)”操作,将数组分为两部分:左子区间(元素均小于基准元素)、右子区间(元素均大于基准元素),最后将基准值放到【左区的右侧】pos上(左区最后一个元素位置);
- 治 (Conquer)
若pos == K-1(找第K小元素,索引从0开始):基准元素即为第K小元素,直接返回;
若pos > K-1:第K小元素在左子区间,递归查找左子区间;
若pos < K-1:第K小元素在右子区间,递归查找右子区间;
- 合 (Combine)
无需合并,找到基准元素的目标位置即可得到结果。
算法步骤:
- 初始化:选择数组第一个元素3作为基准元素pivot,执行分区操作;
- 分区过程:遍历数组,将小于3的元素放左边,大于3的放右边,得到分区后数组:[1, 2, 3, 4, 5],基准元素3的位置pos=2;
- 判断pos与K-1:K-1=1,pos=2 > 1,说明第2小元素在左子区间[1, 2];
- 递归查找左子区间[1, 2]:选择1作为基准元素,分区后数组[1, 2],基准元素1的位置pos=0;
- 判断pos与K-1:pos=0 < 1,说明第2小元素在右子区间[2];
- 递归查找右子区间[2]:区间内只有一个元素2,pos=0(此时pos=K-1=1?不,右子区间的索引需重新计算:原左子区间[0,1],递归时左边界=1,右边界=1,基准元素2的pos=1,等于K-1=1),返回2,即第2小元素。
#include <iostream>
#include <vector>
#include <random>
#include <algorithm>
using namespace std;
// 分区函数:返回基准元素的最终位置pos
int partition(vector<int>& nums, int left, int right) {
// 随机选择基准元素(优化最坏情况)
random_device rd;
mt19937 gen(rd());
uniform_int_distribution<int> dist(left, right);
int pivotIdx = dist(gen);
swap(nums[pivotIdx], nums[right]); // 将基准元素移到区间末尾,方便遍历
int pivot = nums[right]; // 基准元素
int i = left - 1; // i指向“小于基准元素的区间末尾”
for (int j = left; j < right; j++) {
if (nums[j] < pivot) { // 找到小于基准的元素,加入左区间
i++;
swap(nums[i], nums[j]);
}
}
// 将基准元素放到最终位置(i+1)
swap(nums[i+1], nums[right]);
return i+1;
}
// 快速选择核心函数:查找[left, right]区间内的第k小元素
int quickSelect(vector<int>& nums, int left, int right, int k) {
if (left == right) { // 递归终止条件:区间只有一个元素,即为目标
return nums[left];
}
int pos = partition(nums, left, right); // 基准元素的最终位置
if (pos == k - 1) { // 第k小元素的索引为k-1(0开始)
return nums[pos];
} else if (pos > k - 1) { // 目标在左子区间
return quickSelect(nums, left, pos - 1, k);
} else { // 目标在右子区间
return quickSelect(nums, pos + 1, right, k);
}
}
// 对外接口:查找数组中的第k小元素
int findKthSmallest(vector<int>& nums, int k) {
// 边界检查:k必须在[1, nums.size()]范围内
if (k < 1 || k > nums.size()) {
throw invalid_argument("k is out of range");
}
return quickSelect(nums, 0, nums.size() - 1, k);
}
// 扩展:查找第k大元素(转化为第n-k+1小元素)
int findKthLargest(vector<int>& nums, int k) {
int n = nums.size();
return findKthSmallest(nums, n - k + 1);
}
// 测试案例
int main() {
vector<int> nums = {8, 4, 5, 7, 1, 3, 6, 2};
int k1 = 3; // 第3小元素
int k2 = 3; // 第3大元素
cout << "第" << k1 << "小元素:" << findKthSmallest(nums, k1) << endl; // 输出2
cout << "第" << k2 << "大元素:" << findKthLargest(nums, k2) << endl; // 输出3
return 0;
}
输出结果
第3小元素:3
第3大元素:6
三、算法对比
| 对比维度 | 二分查找 | 快速选择 |
|---|---|---|
| 分治核心 | 按“中间索引”拆分区间,舍弃一半无效区间 | 按“基准元素”拆分区间,舍弃一半无效区间 |
| 数据要求 | 必须有序 | 无需有序(原地分区) |
| 时间复杂度 | O(log n)(固定,无最坏情况) | 平均O(n),最坏O(n²)(随机基准可优化) |
| 空间复杂度 | 迭代O(1),递归O(log n) | O(log n)(递归栈深度) |
| 适用场景 | 有序数据的精确查找、边界查找 | 无序数据的Top-K求解、中位数查找 |
四、总结
- 分治思想在查找问题中的核心价值是“缩小问题规模、减少无效操作”;
- 二分查找利用有序数据的特性,通过中间索引快速剪枝,实现O(log n)的高效查找;
- 快速选择借鉴快速排序的分区思想,无需完全排序即可定位Top-K元素,平均效率达到O(n)。
- 两者的共性是“只关注有效子区间,无需处理所有元素”,这也是分治思想在查找问题中优于暴力解法的关键。
学习建议:先掌握二分查找的迭代实现和边界处理,理解“分治剪枝”的核心;再深入快速选择的分区逻辑和随机基准优化,体会“无需全排序即可求解局部问题”的分治优势。通过大量练习(如有序数组的边界查找、海量数据的Top-K筛选),可灵活运用这两种算法解决实际查找问题。
返回顶部